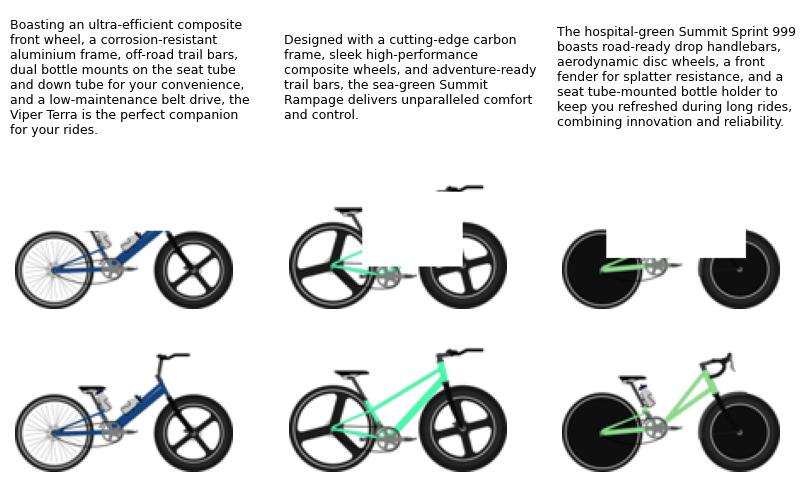
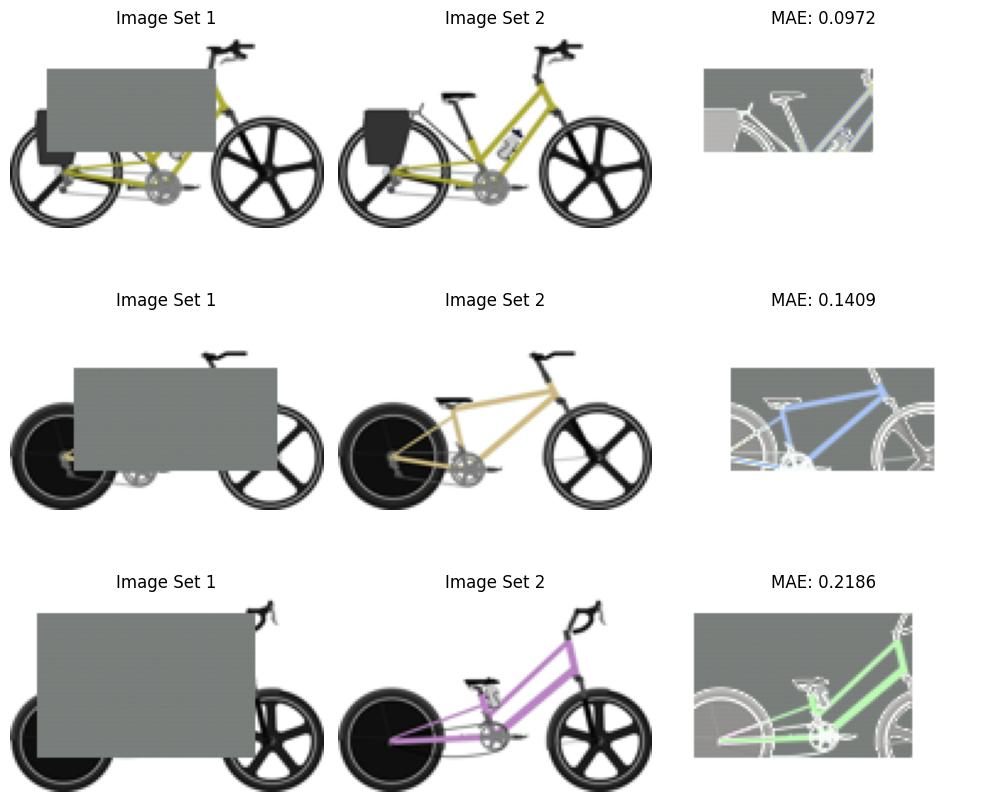
Bike Design Completion
Objective : Automate bike design completion from partial images, descriptions, and parametric data.
Click Here for CodeIntroduction
This project addresses the challenge of completing bike designs from partial inputs, marketing descriptions, and parametric data using generative AI. The goal is to automate the design completion process, enabling rapid visualization of creative concepts while maintaining coherence with the provided inputs. The dataset includes 10,000 training samples and 1,000 test samples comprising partial images, masks, descriptions, and ground truth targets.